Service Desk Optimization: 40 to 80 in No Time Flat

Cost Savings of First Call Resolution (FCR) Improvement. Proven Techniques to Drive First Call Resolution at the Service Desk and add Value to your Organization.
Defining First Call Resolution, aligning results, improving FCR the right way
A First Call Resolution improvement case study
The value of First Call Resolution and metrics
Introduction
The gathering and use of metrics to manage system performance is a common IT practice. Over the last 15 years, similar techniques to assess and manage human performance within IT organizations have been adopted. The Service Desk area within these organizations is a focal point for this practice.
The Service Desk is labor intensive and the use of Automatic Call Distributors (ACD) and request tracking tools provide rich data sets to report against. The Service Desk is the natural place to assess demand, performance, customer satisfaction, problem trends and the impact of adverse events or planned changes.
First Call Resolution (FCR) has become one of the standard Service Desk metrics used to evaluate performance. Service Desks with high FCR rates are successful; they have lived up to several key elements of the Service Desk's value proposition:
- Resolution is delivered close to the customer, speeding time to resolution, minimizing inconvenience and building customer satisfaction
- Routine requests and incidents are resolved by less expensive front line resources
- Specialized engineers on Level 2 and 3 can focus on more demanding tasks
This document begins with a look at how the industry agrees and disagrees on how First Call Resolution (FCR) is measured and a discussion of the intent and value of the metric. A basic method to improve FCR is suggested, followed by a real life example of how this approach has been used and what results it generated.
The value of improved FCR is analyzed in terms of cost savings, direct and indirect benefits. In closing, we summarize the importance of metrics as a management tools for the Service Desk function and suggest some new measures to determine how effective your Service Desk is.
Defining First Call Resolution
In a recent open practitioner forum conducted by the Help Desk Institute (HDI) the definition of First Call Resolution was the topic. The group was comprised of approximately 20 Service Desk leaders from mid-market and enterprise businesses, and external service providers with Service Desk offerings.
As the discussion unfolded, several disconnects arose regarding what "First Call Resolution" means. Some interesting call scenarios were discussed. Participants debated on the handling of e-mails, faxes, voice mail and web requests.
Only a small number of Service Desk leaders considered customer concurrence as pre-requisite for closure, first call or otherwise.
The terms "First Call Resolution", "Tickets Self-Closed", "One-and-Done", and "Closed on Initial Contact" were used almost interchangeably at first.
As the discussion ensued, awareness of nuance distinguishing these terms them grew.
Aging tickets or tickets open overnight - "Are we so focused on the incoming call that we are neglecting other commitments?"
Frequent Flyers - "Are the same people calling the Service Desk over and over? Have we really addressed the underlying issues with them? Can we do something to proactively address their needs?"
% transferred to - "What other teams do we send the most tickets to by volume? By percentage? Why aren't we fixing them ourselves?"
This is a lot of data to collect and analyze, especially if the reporting processes are not automated. While these are clearly best practices, they may not necessarily be the right practice for your Service Desk. With very small teams, the cost or effort to perform this level of reporting regularly can be prohibitive. That doesn't mean these questions should not be asked and answered periodically to keep your FCR metrics meaningful.
Aligning results
A best practice methodology ensures the intent of an SLA or Key Performance Indicator (KPI) is kept top-of-mind when collecting and analyzing that measure. The SLA (or KPI) Pro Forma is a document used to define a measure by its intent, method, inclusions, exclusions, frequency and audience. This document is owned by the Service Desk Manager and is shared with Team Members at each metrics review. It is subject to Change Management and should only be altered with the mutual consent of Key Stakeholders.
An operationally mature Service Desk seeks to add services, expand scope, resolve repetitive problems proactively, and ensure recurring problems are counted as one. As these guidelines are first applied in practice, it is likely they will have a negative impact on FCR rates, even as they begin to reveal underlying quality issues.
As these maturing teams become more focused at adding value, and less concerned with an abstract number, any improvements in First Call Resolution will translate to an improved customer experience and increased value to the IT organization and the customers it serves.
Improving FCR the right way
A Service Desk manager may employ a number of proven techniques to realize meaningful improvement in First Call Resolution. Each of these techniques is based on standard Continuous Quality Improvement methodology.
There is a basic assumption that before something can be managed, it must first be measurable. With metrics in place, improvement requires the following steps be taken:
- Identify opportunities
- Quantify potential benefit or impact
- Estimate required cost or effort
- Prioritize collaboratively
- Set goals or targets
- Develop an action plan
- Embed measures or milestones
- Track to closure
- Confirm success empirically
- Validate results and measurement methods
Case Study
The following Case Study examines a difficult Service Desk situation, and how solid methodology, IT IQ and proven techniques for building organizational effectiveness led to rapid and dramatic increases in First Call Resolution rates, but more importantly improved the quality of service delivery and drove
customer satisfaction to all-time highs.
Background
Giva partner, CDC Global Services, was engaged to provide on-site Service Desk services. We were asked to perform a rapid cut-over, literally arriving Tuesday and providing services on Wednesday. None of the previous Service Desk staff would remain in place to train us or transition knowledge. There was no Knowledge Base, minimal documentation and variable compliance with the small number of processes in place. The client was in the latter stages of a desktop, server and messaging migration and call volume was at record levels.
We anticipated 2,000 calls per month. Abandon rates were over 30%, average waits in the 8+ minute range and long delays to answer and abandon were frequently in excess of 4 hours. The First Call Resolution rate varied dramatically, ranging from as high as 55% and as low as 35%. The second and third level teams regularly resolved more tickets than the Service Desk and were often contacted directly by customers in need of immediate assistance.
Our contract included Service Credits if key Service Level Agreements (SLAs) were missed. The most important of these SLAs was a commitment that the Service Desk would resolve 60% or more of all in-scope calls. We agreed to be accountable after a 90 day stabilization period. Based on the Pro Forma, we estimated about 30% of all requests would be out-of-scope since those services were delivered by other teams, and we simply logged tickets.
We tracked raw FCR daily and weekly and monthly, including in and out of scope calls, see Figure 1. We set an internal minimum of 50%, target of 60%, and stretch goal of 70%. We began reporting under the proposed at 60 days. The results appear in Figure 2.
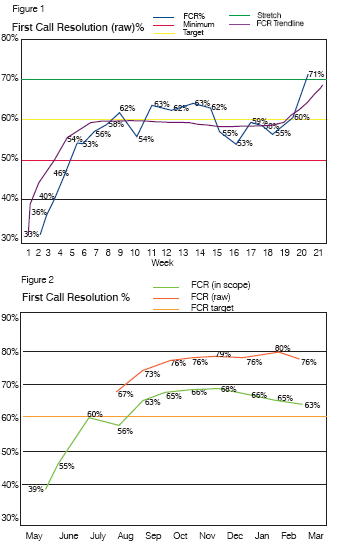
Incidentally, call volume averaged nearly 3000 calls per month, 50% more than expected, over the first 4 months of this engagement.
How we achieved these results
There were three critical phases of growth:
- An initial four week learning period
- A subsequent ten week fine tuning period
- A dramatic spike after 21 weeks where we implemented improved processes
During each phase, we employed proven techniques to drive FCR while we increased our scope to exceed the range of services specified in our contract.
Phase 1- Learning the Environment
During the initial four week period, we rapidly increased our ability to provide FCR. Our focus was three-fold:
- To gather environment-specific knowledge regarding the systems, configuration, dependencies and failure points
- To identify accountabilities, develop relationships and introduce the knowledge transfer process
- To populate our knowledge base, document our learning, and instill internal practices that established the validation and sharing of new information and techniques as we learned them.
The results were dramatic. We quickly built local knowledge, increasing FCR (raw) from less than 40% to 60% in just three weeks as call volume was increased to record levels.
We used several techniques to accomplish these results:
- Regular observation, coaching and feedback sessions with staff
- Daily meetings to discuss learning and experiences
- Regular status reports including sections on lessons learned, achievements and obstacles overcome
- Weekly team meetings where we invited experts from other groups to attend, evaluate our performance to date and provide advice on areas to focus our learning efforts
- An accountability matrix that tracked relationships and responsibilities as we learned them
- An active knowledge transfer process where we proactively identified opportunities for improvement and solicited assistance from up tier teams in building our capabilities
- A flexible, light knowledge base that allowed us to capture and easily search information categorized by system, component, function and task
- An operations manual that clearly outlined support processes, centralized key environmental information and explicitly defined complex procedures for problem determination and fault resolution
Phase 2 - Fine Tuning
As we developed a baseline capability, we implemented a series of actions that allowed us to balance skills across the team and raise our collective competencies. We added new functions, processes and Service Level Expectations (SLE).
Improvement was gradual, but impact was high. The number of tickets we resolved grew as customers returned to or discovered the Service Desk. We instituted a high level of internal reporting, coaching and observation during this period.
We began to produce a series of standard Service Desk reports that allowed us to assess team and individual performance. These reports included:
- Percentage of calls taken by agent, "Who was contributing appropriately?"
- Number of calls taken per agent per hour, by team and by agent, "Who stepped up when volume demanded?"
- Average talk time, by agent, "Who got down to business and got it done quickly?"
- % tickets self-closed, by team, agent and category, "Who could fix what?"
- % tickets closed by Service Desk, not self-closed, by team, agent and category, "Who leveraged the team best?"
- Ratio of calls (and e-mails) to tickets, be team and agent, "Were we logging all requests?"
- Of tickets we did not close, where were they transferred, "What do we need to improve?"
- Of those transfer destinations, who received the most tickets, "How should we prioritize our improvement efforts?"
We enlisted the aid of experienced analysts from other sites to evaluate our performance. Using standard assessment criteria, each team member was assessed multiple times over several weeks. Based on the assessments and metrics, each analyst was challenged with specific performance improvement targets in their respective development areas.
We used techniques like metrics reports, standard operational assessment criteria, performance benchmarks, development plans, cross-functional agendas and meeting formats, standard language and conversation scripting to facilitate rapid implementation and predictable results.
Phase 3 - Optimization
As we reached equilibrium, we formalized a Triage process. No ticket left our team without a review for content, destination and solvability. We achieved true skills leveling by pre-empting the transfer of tickets we could resolve and addressing any proficiency gaps that manifested.
As we began to consistently exceed our SLA, we looked outward for new challenges. The results; we gave back some of the progress we achieved early on toward the metric, but added to overall value and quality by assuming new functions and processes previously out-of-scope for FCR.
The Value of FCR
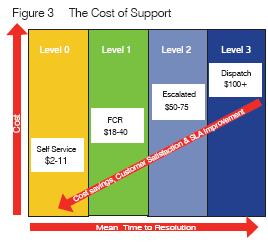
So what is the value gained for all of this effort? It manifests in both direct and indirect ways - to whom? As FCR improves, the overall cost of providing support decreases. Industry analysts estimate the mean cost to resolve a ticket on level one to be about $32. The mean cost to resolve an escalated ticket is about $60 (Figure 3). In an environment averaging 4000 calls per month, improving FCR from 50% to 75% reduces the number of tickets requiring escalation by 1000 per month. The total cost to support those tickets is commensurately reduced yielding an estimated savings of $28,000 per month, based on the averages.
The direct benefit of improved FCR is significant cost savings. Although hard to quantify, the indirect benefits are equally compelling:
- Mean time to resolution is decreased, improving end-user productivity
- Customer satisfaction increases
- Up-tier resources can concentrate on higher level tasks, optimizing system performance and speeding other projects to ROI and completion
- Job satisfaction improves for both Level 1 and Level 2 engineers
- Relations between teams improve
- Level 1 credibility builds, increasing utilization and opening the door for additional FCR opportunities
This holistic set of benefits leads to improvement across all of the quadrants of the Balanced Scorecard, greatly increasing the likelihood of real value and retained benefit.
The Use of Metrics
Using metrics to establish and improve on baseline performance is one key method to deriving optimal performance from your IT teams. Great statistics alone do not achieve results. Long-term quality improvement and cost savings result from nurturing the operational and organizational maturity of those teams and the people on them.
Improvement begins with awareness. Keep the end goal in mind. Make sure your measures are meaningful and accurate. Include 360 measures like client satisfaction or operational maturity when assessing the performance of your teams.
In this way, you can be sure your metrics most accurately reflect the Quality of those teams' performances. With accurate measures, you can begin to manage to unprecedented results.